Pythonで設定ファイル(.xml)の読み込みと書き換えをする
補足
標準モジュールが全部カバー
サンプルプログラム
今回はxmlを取り上げることにして、気が向いたらjsonを試してみる。
作ったプログラムはありふれた内容だが、[Read]ボタンで設定ファイルから値を読み込んでテキストボックスに表示、[Write]ボタンでテキストボックス上で編集した内容を設定ファイルに書き込む、というもの。
〇[Read]ボタンを押すとconfig.xmlの値をテキストボックスに表示する


〇[Write]ボタンを押すとconfig.xmlにテキストボックスの値を書き込む


ソースコード
# ReadWriteXML_001.py # Python 3.8.1 import tkinter as tk import xml.etree.ElementTree as ET class App(tk.Frame): def __init__(self, master=None): super().__init__(master) self.pack() self.create_widgets() def create_widgets(self): ## Make instances self.ent1 = tk.Entry(self, width=50) self.ent2 = tk.Entry(self, width=50) self.ent3 = tk.Entry(self, width=50) self.lb1 = tk.Label(self, text="ent1:") self.lb2 = tk.Label(self, text="ent2:") self.lb3 = tk.Label(self, text="ent3:") self.bt1 = tk.Button(self, text="Read", width=6, command=self.read_xml) self.bt2 = tk.Button(self, text="Write", width=6, command=self.write_xml) ## Place them self.lb1.grid(row=0, column=0, padx=5, pady=5, sticky=tk.W) self.lb2.grid(row=1, column=0, padx=5, pady=5, sticky=tk.W) self.lb3.grid(row=2, column=0, padx=5, pady=5, sticky=tk.W) self.ent1.grid(row=0, column=1, columnspan=2, padx=5, pady=5) self.ent2.grid(row=1, column=1, columnspan=2, padx=5, pady=5) self.ent3.grid(row=2, column=1, columnspan=2, padx=5, pady=5) self.bt1.grid(row=3, column=1, padx=5, pady=5) self.bt2.grid(row=3, column=2, padx=5, pady=5) def read_xml(self): try: tree = ET.parse('config.xml') root = tree.getroot() text_ent1 = root.find("./setting/ent1").text text_ent2 = root.find("./setting/ent2").text text_ent3 = root.find("./setting/ent3").text self.ent1.delete(0, tk.END) self.ent2.delete(0, tk.END) self.ent3.delete(0, tk.END) self.ent1.insert(0, text_ent1) self.ent2.insert(0, text_ent2) self.ent3.insert(0, text_ent3) except Exception: print("例外エラー") else: print("XML読み込み完了") def write_xml(self): try: tree = ET.parse('config.xml') root = tree.getroot() text_ent1 = self.ent1.get() text_ent2 = self.ent2.get() text_ent3 = self.ent3.get() root.find("./setting/ent1").text = text_ent1 root.find("./setting/ent2").text = text_ent2 root.find("./setting/ent3").text = text_ent3 tree.write('config.xml') except Exception: print("例外エラー") else: print("XML書き込み完了") if __name__ == "__main__": root = tk.Tk() app = App(master=root) app.mainloop()
PythonでBASLERのカメラを制御する ~インストールの忘備録~

Source of photo:https://github.com/basler/pypylon
マシンビジョン業界で有名なBASLER社。産業用カメラの豊富なラインナップを展開していて、仕事で何かとお世話になることが多い。そんなBASLERカメラをPythonで制御するための環境を構築したので忘備録を残しておく。
インストール手順は色んなサイトで紹介されているので割愛する。
- GitHub - basler/pypylon: The official python wrapper for the pylon Camera Software Suite
- (01)Python+pypylonで産業用カメラ制御: WAKU-TAKE-A PROGRAM
環境
パソコン
windows10 64bit
pylon
インストーラー : Basler_pylon_6.1.1.19832.exe
pylonバージョン詳細 : 下図参照

python
Python3.8.1 32bit
pypylon
whlファイル : pypylon-1.5.4-cp38-cp38-win32.whl
※ whlファイルのインストール方法は他でも使えるので記載しておく。
1. whlファイルを適当なフォルダに保存する。
2. コマンドプロンプトでwhlファイルを保存したディレクトリに移動する。
C:\***\***>cd C:\***\***\***\Python\Python38-32
3. pipでwhlファイルを指定してインストールする。
C:\***\***\***\Python\Python38-32>pip install pypylon-1.5.4-cp38-cp38-win32.whl
動作確認
- aceシリーズでUSB3インターフェースのカメラを使う。
GitHubからサンプルソース grab.pyGitHubからguiimagewindow.py をダウンロードする。grab.pyguiimagewindow.pyを実行して、以下の画面が表示されればOK。

Pythonでsecretsモジュールを使ってパスワードを自動生成する
- Pythonでパスワード作るには
secrets.choice()を使った方が良いと言われているけど、random.choice()と何が違うのか? random.choice()で作成されたパスワードは予測される可能性がある。パスワードを構成するすべての文字がランダムに選ばれたように見えて実はどんな文字が選ばれているのかを第三者が計算することができる。 対して、secrets.choice()はより予測が難しくなったもの。
注意事項
secretsモジュールはより安全であると紹介しているサイトを見かけますが、PEP506のQ/Aに「専用の暗号化ソフトウェアの代用にはならない」との記述があります。過度な信頼をしてはいけないと私は解釈しました。
この記事はrandom.choice()よりはsecrets.choice()のほうがベターだよね、ということをお伝えするのが目的であり、安全であるとお伝えする意図は一切ありません。ご使用は自己責任でお願いします。
解説
random.choice()
random.Randomクラスの関数であり、Mersenne Twisterという乱数発生器(アルゴリズム)を使用しているが、暗号化の目的には向いていない。
実は、randomモジュールは別に random.SystemRandomクラス も提供していて、このクラスはOSがもつ乱数発生器を利用して乱数を作成する。
secrets.choice()
secrets.SystemRandomクラスの関数であり、このクラスもOSがもつ乱数発生器を利用して乱数を作成する。
サンプルプログラム
アルファベットの大文字と小文字、数字0~9の中から10文字をランダムに選びパスワードを作成する。そして、パスワードをクリップボードにコピーし、念のためテキストファイル(.txt)にしてデスクトップにも保存する。というプログラム。

import os import datetime import string import secrets import ctypes import pyperclip #Determine password length len_pw = 10 #Create password def create_pw(length): chars = string.ascii_uppercase + string.ascii_lowercase + string.digits pw = ''.join([secrets.choice(chars) for i in range(length)]) return pw #Save as txt def save_txt(password): now = datetime.datetime.now() filename = "PassWord_{:%Y%m%d%H%M%S}.txt".format(now) desktop = os.getenv("HOMEDRIVE") + os.getenv("HOMEPATH") + "\\Desktop" with open(os.path.join(desktop, filename), mode='a') as f: f.write(password) def main(): x = create_pw(len_pw) save_txt(x) pyperclip.copy(x) ctypes.windll.user32.MessageBoxW( 0, "パスワードをクリップボードにコピーしました", "Complete!!", 0x00000040) if __name__ == '__main__': main()
Pythonでグラフのプロットとプロットの間の値を読み取る
- 実験で〇〇を測定したけど測定間隔が粗かった。データとデータの間にある値が欲しんだけど…
interpolateのスプライン補間でデータ数を増やす。※あくまでもデータの“補間”ですのでその意味をちゃんと理解してご使用ください。
解説
スプライン補間の詳細はググってもらうとして、interpolateの使い方は以下のサイトが非常にわかりやすかった。応用例は↓↓のサンプルプログラムを参照してほしい。
org-technology.com
サンプルプログラム
エクセルからデータを読み込んで、任意の「横軸の値」を与えるとそれに対応するデータを返すというプログラム。
元データは以下のようにエクセルで表形式で保存してあるとする。A列が横軸データ、B列が縦軸データとなっている。見てのとおりデータ数は26個。
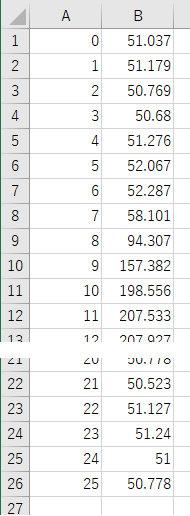
これをデータ数1000個でスプライン補間すると以下の青線グラフになる。赤線は元データのグラフ。
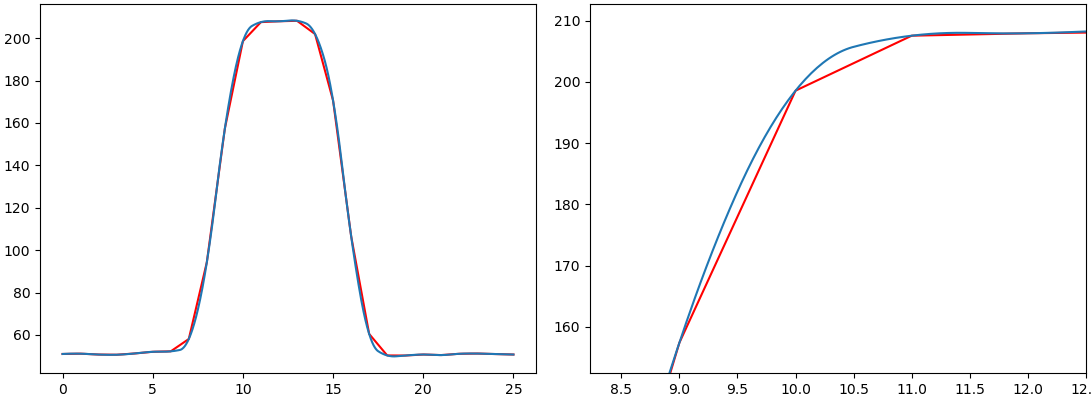
ここで、例えば課題のレポートに横軸が10.5における測定値が必要だったことが後からわかったとする。元データには存在しないので再測定するか…もしくは、スプライン補間したデータを求めるか。サンプルプログラムでは44行目、48行目のようにすることでスプライン補間結果から値を得ている。
x=10.5に対応するyは205.713です
ソースコード
# 37_SplineCurve_001.py # python 3.8.1 # openpyxl 3.0.3 # coding: utf-8 import numpy as np from scipy import interpolate from matplotlib import pyplot as plt import openpyxl def read_excel(wb_path): col_A = [] col_B = [] wb = openpyxl.load_workbook(wb_path) sheet_list = wb.sheetnames sheet = wb[sheet_list[0]] num_data = sheet.max_row for i in range(1, num_data+1): cell = sheet.cell(row=i, column=1) col_A.append(cell.value) cell = sheet.cell(row=i, column=2) col_B.append(cell.value) return col_A, col_B def interpolate_spline(data_x, data_y, xoi): data_x_min = min(data_x) data_x_max = max(data_x) interpolated_func = interpolate.interp1d(data_x, data_y, kind="quadratic") corr_data_x = np.linspace(data_x_min, data_x_max, 1000) corr_data_y = interpolated_func(corr_data_x) # plt.plot(data_x, data_y,"r") # plt.plot(corr_data_x, corr_data_y) # plt.show() return interpolated_func(xoi) if __name__ == '__main__': xoi = 10.5 #欲しいy値に対応するx値 (X of Interest) wb_path = 'OriginalData.xlsx' x, y = read_excel(wb_path) yoi = interpolate_spline(x, y, xoi) #欲しいy値を求める (Y of Interest) print("x={}に対応するyは{:.3f}です".format(xoi, yoi))
Pythonで自動化!Outlookメールを自動送信する
- STMPサーバー?よく分からない…それを使わずにメールを自動送信する方法あるか?
win32comモジュールを使ってOutlookを操作する
解説
Pythonでメール操作する方法をググるとstmplibを使用する方法が多く出てくる。この方法はSTMPサーバーやパスワードを指定する必要があり、詳しくない人だとちょっと忌避感があるかもしれない。そこで、手軽に実現する方法としてwin32comを使用する。サーバーとかパスワードの指定不要!
コードも簡単これだけ↓↓で、勝手にOutlookが立ち上がってメールが送信される。
from win32com import client outlook = client.Dispatch('Outlook.Application') new_email = outlook.CreateItem(0) new_email.BodyFormat = 1 new_email.To = '送信メールアドレス' new_email.Subject = 'タイトル' new_email.Body = '本文' new_email.Send()
Line 4
メールの書式設定を選択する。
1:テキスト 2:HTML 3:リッチテキスト

Line 5,6,7
必要事項をここにべた書きするか、変数でもよい。
Line 8
このタイミングでメールが送信される。動作確認したい場合は代わりにnew_email.Display(True)を入れておく。送信前のメール画面が確認できる。
サンプルプログラム
毎日、朝9時と夕方18時に上司にメール連絡を入れるプログラムを作成した。リモートワークの勤怠管理のための定時連絡を自動化する、という想定。
- 朝9時に送信されるメール画面。キャプチャーするために
new_email.Display(True)で送信しないように止めている。

- 夕方18時に送信されるメール画面。
ソースコード
# 36_EmailAutomatically_001.py # python 3.8.1 # schedule 0.6.0 # coding: utf-8 import time from win32com import client import schedule def makeEmail(set_subject, set_body): outlook = client.Dispatch('Outlook.Application') new_email = outlook.CreateItem(0) #フォーマットを指定する。1:テキスト 2:HTML 3:リッチテキスト new_email.BodyFormat = 1 #送信先メールアドレス new_email.To = 'test1@test.com; test2@test.com' new_email.CC = 'test3@test.com' #メールタイトル new_email.Subject = set_subject #メール本文 new_email.Body = set_body #メール送信実行 new_email.Display(True) #Outlookの新規メール画面が開くとこまで # new_email.Send() #問答無用で送信するモード def main(): #朝用の定型文 subj_morning = "[連絡]業務開始" body_morning = "〇〇さん\n業務開始します。\n□□" #夕方用の定型文 subj_afternoon = "[連絡]業務終了" body_afternoon = "〇〇さん\n業務終了します。\nお疲れさまでした。\n□□" #朝9時と、夕方18時にタイマーをセットする schedule.every().day.at("9:00").do(makeEmail, subj_morning, body_morning) schedule.every().day.at("18:00").do(makeEmail, subj_afternoon, body_afternoon) while True: schedule.run_pending() time.sleep(1) if __name__ == '__main__': main()
参考サイト
Pythonで自動化!複数画像から輝度値を取得してテキストに出力する
- 画像から輝度値を抽出したいが、大量にあるので自動化したい。
filedialog.askopenfilenamesを使ってファイルダイアログで複数画像を一括で選択できるようにする。
解説
filedialog.askopenfilenamesの使い方
filetypesで開くファイルの種類を指定、initialdirでデフォルトパスを指定するだけ。ちなみに...namesのsを抜くとファイルが1個しか選択できない。複数選択したい場合はsを忘れないこと。filesはタプル型になり、選択したファイルのパスが格納される。なので、このタプルをfor文でアンパックしてあげれば一括処理ができる。
files = filedialog.askopenfilenames(filetypes = ***, initialdir = ***)
サンプルプログラム
デスクトップに保存されている赤、青、緑の3枚の画像から一括で輝度値を取得してテキストに出力するプログラムを作成した。
- 下の画像はファイルダイアログで画像を選択するところ。

- 下の画像は出力結果。※見やすいように後から編集で適当にスペースを入れてある。

ソースコード
# 35_GetIntensity_001.py # python 3.8.1 # opencv-python 4.1.2.30 # coding: utf-8 import os import datetime import cv2 import tkinter as tk from tkinter import filedialog def getBGR(path): imgBGR = cv2.imread(path, cv2.IMREAD_COLOR) #開いた画像からRGBを抽出する。 b = imgBGR.T[0].flatten().mean() g = imgBGR.T[1].flatten().mean() r = imgBGR.T[2].flatten().mean() return b, g, r def main(): root = tk.Tk() root.withdraw() #出力するファイルの名前を定義する。タイムスタンプ付き。 now = datetime.datetime.now() fo = 'ImageIntensityList_{:%Y%m%d%H%M%S}.txt'.format(now) #ファイルダイアログのデフォルトパスをデスクトップにする。 desktop_path = os.getenv("HOMEDRIVE") + os.getenv("HOMEPATH") + "\\Desktop" #対象ファイルのタイプをTiffに限定する。 target_format = [('TIF image', '*.tif')] #ファイルダイアログオブジェクトの作成。複数ファイル選択できる。 files = filedialog.askopenfilenames(filetypes = target_format, initialdir = desktop_path) #ファイルダイアログで選択したすべてのファイルを処理する。 with open(os.path.join(desktop_path, fo), mode='a') as f: f.write('File path,B,G,R,Intensity\n') for file in files: b, g, r = getBGR(file) i = 0.298912 * r + 0.586611 * g + 0.114478 * b #RGBから輝度値を算出 line = '{0},{1:.2f},{2:.2f},{3:.2f},{4:.2f}\n'.format(file, b, g, r, i) f.write(line) if __name__ == '__main__': main()
Pythonのlist.sort()とsorted(list)の違いは新たにリストが作られるかどうか
- list.sort()とsorted(list)の使い分けは?
- 対象となるリストを作り替えてもいい場合は list.sort() を、対象となるリストを残しておきたい場合は sorted(list) を使う
解説
list.sort()
sortメソッドは対象リストに直接変更を加えるソートを行う。これを「インプレイスでソートする」と言う。以下コード内の#1と#2が示すように、ソート前後でオブジェクトIDが変わっていないことがわかる。
data = ["Green", "Blue", "Red", "Yellow", "Orange", "Brown", "Black"] print("Object ID:", id(data)) #1 data.sort() print("Result :", data) print("Object ID:", id(data)) #2
Object ID: 86722536 #1 Result : ['Black', 'Blue', 'Brown', 'Green', 'Orange', 'Red', 'Yellow'] Object ID: 86722536 #2
sorted(list)
sorted関数は対象リストとは別の新しいリストを作り、ソートした要素を入れる。以下コード内の#3と#4が示すように、sort関数から返ってくるとオブジェクトIDが変わっていることからも分かる。
data = ["Green", "Blue", "Red", "Yellow", "Orange", "Brown", "Black"] print("Object ID:", id(data)) #3 print("Result :", sorted(data)) print("Object ID:", id(sorted(data))) #4
Object ID: 86722504 #3 Result : ['Black', 'Blue', 'Brown', 'Green', 'Orange', 'Red', 'Yellow'] Object ID: 86721800 #4
Tips ~Pythonのソートは安定している~
『安定』とは、ソート基準が同等のデータはソート前の順番が保持される、ということを意味する。細かいことだが、これを知らないとkeyパラメータに複数条件を入れる…なんて無駄なことをやってしまいかねない。と思ったら、過去に挙げた記事でまんまそれをやってしまっていた。
greenhornprofessional.hatenablog.com
文字数でソートする例
Green, Brown, Blackは5文字なので、同等データとなるがちゃんとソート前の順序が保持されていることがわかる。
data = ["Green", "Blue", "Red", "Yellow", "Orange", "Brown", "Black"] data.sort(key=len) print(data)
['Red', 'Blue', 'Green', 'Brown', 'Black', 'Yellow', 'Orange']